<데이터 시각화 01>
seaborn 라이브러리
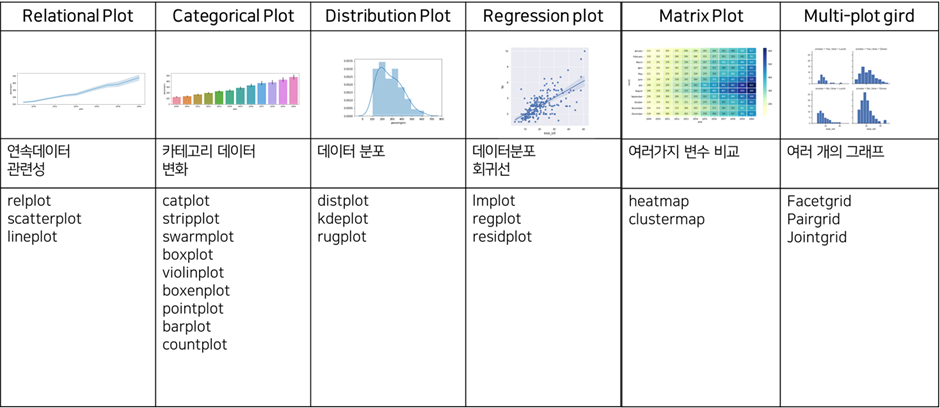
이전에 간단히 소개한 대로, seaborn 라이브러리는 시각화를 위한 다양한 그래프를 제공하는 도구입니다.
seaborn은 일반적으로 x,y, data에 대한 정보를 지정해야 함.
장점: 고급 통계 기능을 그래프 내부적으로 제공하고 있습니다.
단점: 데이터 크기가 클수록 속도가 느려집니다.
그래프 그려보기
표시해야 할 데이터가 많아질수록 가독성은 낮아진다.

다양한 설정을 통해 가독성을 향상시킬 수 있다.

<데이터 시각화 02>
위경도 데이터 scatterplot으로 시각화하기
df_seoul["시군구명"].value_counts()우선 서울 각각의 시군구에 얼마나 많은 병원이 있는지 출력해봤습니다.
df_seoul["시군구명"].value_counts().plot.bar(figsize=(10,4), rot=30)이후 해당 데이터를 간단히 bar 그래프로 시각화해봤습니다. 이는 이미 배운 내용과 동일하죠.
plt.figure(figsize=(15,4))
sns.countplot(data=df_seoul, x="시군구명")첫번째 줄을 통해 시각화할 차트의 크기를 가로 15인치, 세로 4인치로 미리 지정합니다. (그러지 않을 경우 레이블이 겹쳐서 읽기 힘들기 때문)
두번째 줄은 seaborn 모듈의 countplot 함수를 사용하는 sns.countplot을 통해 df_seoul 데이터프레임의 시군구명 열의 값들을 x 레이블로 지정하여 그래프로 시각화합니다.
| Q: plot은 인수로 figsize를 지정할 수 있는데, countplot은 왜 안되나요? countplot은 seaborn 라이브러리의 함수이고, seaborn은 matplotlib 기반으로 만들어진 라이브러리입니다.
countplot은 Figure-level function이 아니라 Axes-level function입니다. 즉, countplot은 Figure를 생성하지 않고 Axes를 생성합니다. 따라서 countplot을 호출하기 전에 matplotlib.pyplot의 figure 함수를 사용하여 Figure를 생성하고 크기를 지정해야 합니다. Figure는 그래프가 그려지는 캔버스와 같고, Axes는 Figure 안에 그려지는 그래프입니다. matplotlib.pyplot의 plot 함수는 Figure-level function이기 때문에 figsize 인수를 사용하여 Figure의 크기를 지정할 수 있습니다. |
df_seoul[["경도","위도","시군구명"]].plot.scatter(x="경도",y="위도",figsize=(8,7),grid=True)기본적인 scatter plot을 사용해서 시군구명에 위치한 병원들을 위치별로 시각화해보겠습니다.

plt.figure(figsize=(9,8))
sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="상권업종중분류명")이번에는 seaborn의 scatterplot을 활용해서 hue옵션을 추가해보겠습니다.
hue 옵션은 특정 인수를 기준으로 시각화를 구분해서 처리해주기에 좀 더 구체적인 데이터를 추출할 수 있습니다. (우측 상단에 분류된 카테고리는 덤으로 같이 나옵니다, 만약 표시하지 않고 싶으면 legend=False 인수만 추가하면 됩니다)

plt.figure(figsize=(9,8))
sns.scatterplot(data=df, x="경도", y="위도", hue="시도명")
사용할 데이터프레임을 서울이 아닌 전체 도시가 포함된 데이터로 활용하면 위와같이 전국에 분포된 데이터를 시각화할 수도 있습니다.
<데이터 시각화 03>
Folium을 사용하여 실제 지도에 시각화하기
scatter plot은 수치형 데이터가 어디 좌표에 위치하는지 출력할 때 주로 사용됩니다.
보통 상관계수(correlation coefficient/ 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관 관계의 정도를 수치적으로 나타낸 계수), 회귀선(회귀선(回歸線)은 연중 태양이 지상에 직각으로 비추는 때가 있는 지역의 남과 북의 위도 경계이다.)을 출력하는데 사용하며 지리 데이터에서도 사용이 가능합니다.
scatter plot은 데이터가 대략 어느 위치에 있는지 확인할 수 있지만,정확한 위치는 확인이 어렵습니다. 이때, folium을 사용하면 좋습니다.
| import하기 Folium을 사용하기 위해선 직접 Anaconda prompt에 conda install -c conda-forge folium을 입력하여 설치합니다.
아나콘다가 아닌 google colab을 사용하면 바로 import folium으로 불러오면 됩니다. |
map = folium.Map(location=[df_seoul_hospitals["위도"].mean(),df_seoul_hospitals["경도"].mean()], zoom_start=13)
map그냥 Map만 출력하면 세계지도가 나오지만, location과 zoom_start를 사용하면 시작 위치를 설정할 수 있습니다.
for n in df_seoul_hospitals.index:
name = df_seoul_hospitals.loc[n, "상호명"]
address = df_seoul_hospitals.loc[n, "도로명주소"]
popup = f"{name}-{address}"
location = [df_seoul_hospitals.loc[n, "위도"], df_seoul_hospitals.loc[n, "경도"]]
folium.Marker(
location = location,
popup = popup,
).add_to(map)
mapfor문을 사용해서 각 병원의 위도와 경도에 해당하는 위치를 marker로 표시하면 실제 지도에서 해당 위치가 표시된 모습을 확인할 수 있습니다.

<데이터 시각화 04>
히스토그램으로 전체 수치 데이터 시각화하기
| 히스토그램 (Histogram) | matplotlib 메소드 | seaborn 메소드 |
| •데이터의 빈도수 및 분포를 알아보기 위해 작성하는 그래프 •카테고리별 개수를 막대로 나타내는 막대그래프와 달리, 정해진 구간별 빈도수를 막대로 나타내어 분포를 볼 수 있는 통계분석 도구임 |
plt.hist() | sns.histplot() |
df.hist로 출력해보면 모든 열에 대한 데이터를 시각화해서 출력합니다.

iloc[] 를 사용하면 특정 행과 열의 범위를 지정해서 사용할 수 있습니다. (슬라이싱)
iloc[row_num, col_num]
df.iloc[:,:12].hist(figsize=(12,12))
plt.show()슬라이싱을 이용하여 맨 처음 열부터 12개 열에 대한 데이터로 히스토그램을 그립니다.
'Data Science(w. naver boostcourse)' 카테고리의 다른 글
| 10. 텍스트 데이터 전처리 (0) | 2024.10.22 |
|---|---|
| 9. 데이터 색인하기 (0) | 2024.10.21 |
| 7. 데이터 요약하기 (0) | 2024.10.10 |
| 6. 결측치 다루기 (8) | 2024.10.04 |
| 5. 데이터 미리보기 및 요약하기 (3) | 2024.10.03 |