기초 통계값
* 데이터의 타입은 dtypes를 통해 확인 가능.
df["위도"].dtypes
기존에 불러온 상가업소정보 데이터를 기반으로 실습을 해보자.
df["위도"] 를 출력하면 위도라는 column의 데이터만 확인할 수 있다.
위 사진에서 보다싶이, Google Colab에서는 굳이 .dtypes 함수를 사용하지 않더라도 하단에 타입이 같이 출력되긴 한다.
1. 평균값
mean()을 사용하면 해당 값들의 평균값을 확인할 수 있다.

2. 중앙값
median()을 사용하면 전체 데이터의 중앙값을 확인할 수 있다. (가운데 데이터의 값)

3. 최대값
max()를 사용하면 해당 데이터 중 가장 큰 값을 확인할 수 있다.

4. 최소값
min()을 사용하면 가장 작은 값을 확인할 수 있다.

5. 데이터 개수
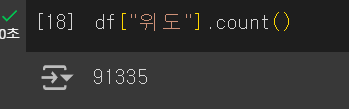
count()를 사용하면 데이터들의 개수를 확인할 수 있다.
요약값 확인
df["위도"].describe()는 해당 컬럼의 데이터들의 특징을 요약해서 보여준다.

25% = 앞에서 1/4 에 해당하는 값이고, 1사분위수라고 부른다.
50% = 중앙값에 해당하며, 2사분위수라 부른다. (median값과 동일)
75% = 3/4 에 해당하는 값이고, 3사분위수라 부른다.
df["위도"].describe() 처럼 1개의 데이터만 출력할때는 series 데이터 타입이지만, 2개 이상은 2차원 구조가 적용되므로 DataFrame 형식으로 적용된다.

DataFrame은 2차원 배열에 속하므로 list 형태로 column을 넣어야 합니다. 따라서 대괄호를 2번 사용.
특정 데이터만 요약하기
df.describe(include="number") > 숫자로 이루어진 데이터만 요약
df.describe(include="object") > 문자열 데이터만 요약

top은 가장 높은 빈도의 데이터를 보여주고, freq는 top 데이터의 빈도수를 표시.
* 결측치는 요약하지 않습니다.
중복값 제거
df.describe(include="object")와 같이 문자열 데이터 요약을 확인해 보면 unique라는 수치가 확인됩니다.
unique는 값의 종류가 몇 개인지를 표시합니다.
unique 값이 1인 경우 오직 1개의 값이 존재하는 것을 의미합니다.

위 이미지처럼 상권업종대분류명 컬럼의 데이터는 오직 의료 밖에 없다는 것을 알 수 있습니다.
nunique()를 사용하면 실제 데이터가 아닌 int형 값으로 몇개의 unique 값이 있는지 확인 가능합니다.
len(df["상권업종대분류명"].unique()) 는 nunique()를 사용한 것과 같은 값을 출력한다.
요약값 그룹화하기
.value_counts() 를 통해 특정 값이 몇번 반복되는지 확인할 수 있습니다.

위 사진을 보면 지점명 컬럼에서 '장례식장' 값을 가진 데이터가 97개 존재하는 것을 확인할 수 있습니다.

여기서 옵션 normalize=True 를 추가해 주면 해당 값이 차지하는 비율을 계산해줍니다.
시도별 데이터를 normalize하고 변수에 저장한다음 bar 그래프로 시작해보면 어디에 가장 많이 위치하는지 한눈에 볼 수 있다.

(pie차트로도 표현이 가능하지만, 직관적인 비교가 어렵다는 단점으로 인해 pie 차트는 향후 업데이트 계획이 없다)
'Data Science(w. naver boostcourse)' 카테고리의 다른 글
| 9. 데이터 색인하기 (0) | 2024.10.21 |
|---|---|
| 8. 데이터 시각화 (Visualization) (4) | 2024.10.11 |
| 6. 결측치 다루기 (8) | 2024.10.04 |
| 5. 데이터 미리보기 및 요약하기 (3) | 2024.10.03 |
| 4. 파일 경로 설정 및 불러오기 (0) | 2024.08.26 |